
Para acessar com segurança os arquivos do Azure Data Lake Storage Gen 2 a partir do Azure Databricks, uma boa solução é configurar um Service Principal com as políticas de acesso adequadas concedidas ao seu data lake, para que ele sirva como um intermediário. Desse modo, você não precisa expor as chaves de sua conta de armazenamento a todos os usuários do workspace do Databricks.
Antes de mais nada, você precisa registrar uma aplicação no Azure Active Directory (AAD). Posteriormente, você vai usá-la de dentro do Azure Databricks, com OAuth 2.0, para autenticar no ADLS Gen 2 e criar uma conexão de um arquivo ou diretório específico dentro do data lake, com o Databricks File System (DBFS). Essas conexões são chamadas mount points. Elas apresentam a opção de acessar esses arquivos ou diretórios usando uma abstração padrão de sistemas de arquivos que pode ser facilmente compreendida pelos múltiplos usuários do workspace.
Não conseguiu entender uma única palavra do que eu disse? Vem comigo que eu te explico tudo!
Configurando um Service Principal no Azure AD
Primeiramente, você precisa criar um registro de aplicação no Azure Active Directory (AAD), seguindo os passos abaixo.
- Entre em sua conta através do portal Azure e selecione Azure Active Directory.
- Selecione App registrations.
- Selecione New registration.
- Dê um nome para a sua aplicação e, após definir os outros campos como na imagem abaixo, selecione Register.
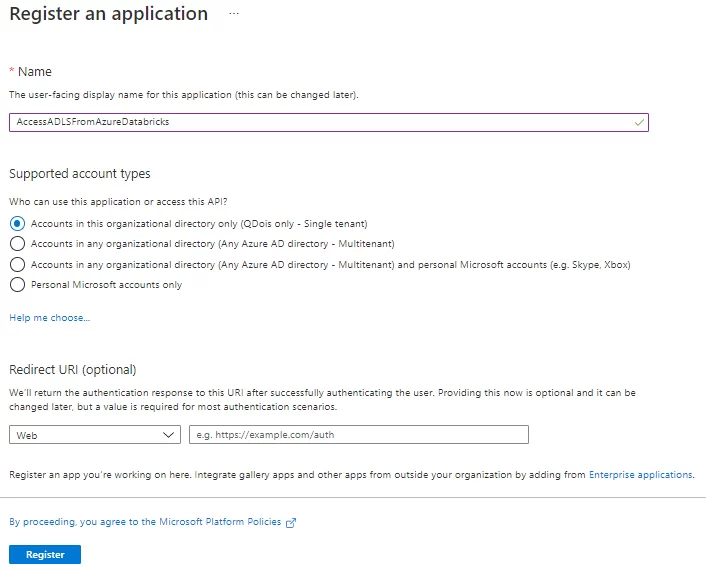
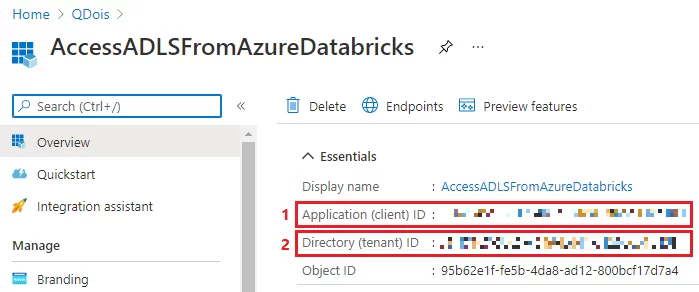
Após registrar sua aplicação, no Overview você pode ver o Application ID e o Directory ID. Anote-os porque eles serão utilizados mais tarde nesta configuração.
Criando um segredo para acessar seu Service Principal
A aplicação Azure AD que você criou é o seu Service Principal. Ele funciona como um usuário dentro do seu Active Directory do tipo de serviço, que consegue realizar logins em outros recursos Azure e acessar dados deles conforme você precisar.
Mas para se referir a ele a partir de outras ferramentas, você deve criar um segredo para a aplicação, que é basicamente a senha do seu Service Principal. Essa senha pode ser armazenada em um Azure Key Vault em sua assinatura, para que você não tenha que referenciá-la diretamente do seu código.
- Dentro da sua aplicação, selecione Certificates & secrets.
- Abaixo de Client secrets, selecione New client secret.
- Forneça uma descrição para o segredo criado e sua duração. Quando terminar, selecione Add.

- Após criar o segredo, o seu valor será exibido. Copie esse valor porque não será possível recuperá-lo mais tarde. Você usará o segredo em conjunto com o Application ID anotado para registrar-se com o Service Principal.

- Agora, precisamos armazenar o valor do segredo no Azure Key Vault (AKV), para ser posteriormente referenciado de forma segura a partir do Azure Databricks. Assim, dentro de seu Recurso AKV, selecione Secrets, depois Generate/Import e crie um segredo com o nome ‘ADLS-DATABRICKS-KEY’ e o valor do segredo copiado para o campo ‘Value’.

Criando um secret scope do Databricks
A fim de acessar os segredos armazenados dentro de seu Azure Key Vault, um secret scope deve ser configurado no workspace do Databricks.
- Verifique se você tem permissão de Contributor no recurso do Azure Key Vault que deseja usar para configurar o secret scope.
- Vá para https://<sua-instancia-do-databricks>#secrets/createScope.
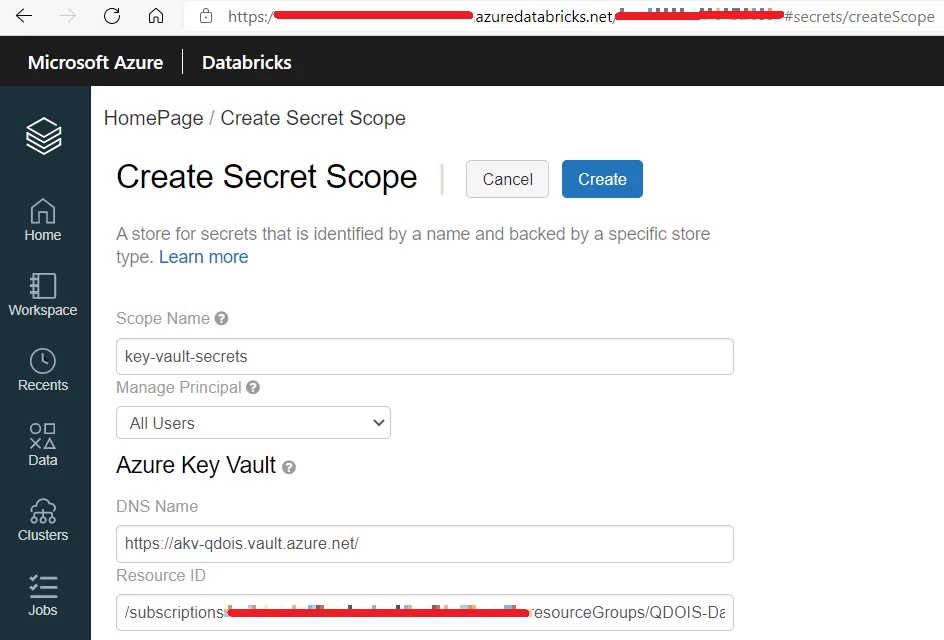
- Digite o nome do seu secret scope.
- No menu Manage Principal, permita que todos os usuários gerenciem esse secret scope. O ideal é que cada usuário do seu workspace Databricks tenha a permissão mais adequada para o secret scope, conforme ele será usado. Você pode, por exemplo, limitar o acesso de alguns usuários para somente ler ou listar os segredos armazenados no seu Azure Key Vault. Entretanto, esse controle fino de permissões somente pode ser realizado através do Databricks Premium Plan.
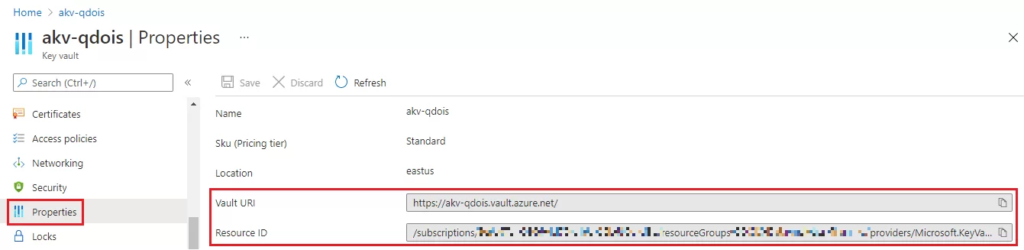
- Preencha o DNS Name e o Resource ID referentes ao seu Azure Key Vault. Essas informações estão disponíveis na seção de Properties do seu AKV no portal Azure. O DNS Name corresponde ao campo ‘Vault URI’.
- Clique no botão Create.
Agora, toda vez que você precisar acessar um segredo do Key Vault de dentro do Databricks Workspace (por exemplo, uma senha do usuário de uma API), esse secret scope pode ser usado para fazer referência ao Azure Key Vault, no qual os segredos estão armazenados, e se conectar a ele.
Concedendo as permissões ao Service Principal no ADLS Gen2
O Service Principal precisa ter um role assignment configurado para ele na sua conta de armazenamento para poder acessar os arquivos dentro dela. Esse role depende de como você quer usar os arquivos que você deseja acessar no data lake:
- Storage Blob Data Owner: use para definir posse e gerenciar controles de acesso POSIX para o Azure Data Lake Storage Gen2.
- Storage Blob Data Contributor: use para conceder permissões de ler/escrever/apagar os recursos armazenados no Blob.
- Storage Blob Data Reader: use para conceder permissões somente de leitura aos recursos armazenados no Blob.
Nota: Apenas os roles explicitamente definidos para acesso de dados permitem ao Service Principal acessar o conteúdo de arquivos armazenados na sua conta de armazenamento. Assim, roles superiores como Owner, Contributor e Storage Account Contributor permitem ao Service Principal apenas gerenciar a conta de armazenamento, mas não fornecem acesso ao conteúdo dos dados armazenados nela.
Para configurar isso, siga os passos abaixo:
- Dentro da sua conta de armazenamento, selecione Access Control (IAM) para exibir as configurações de controle de acesso para ela. Selecione Add e depois a opção Add role assignment para adicionar um novo role.
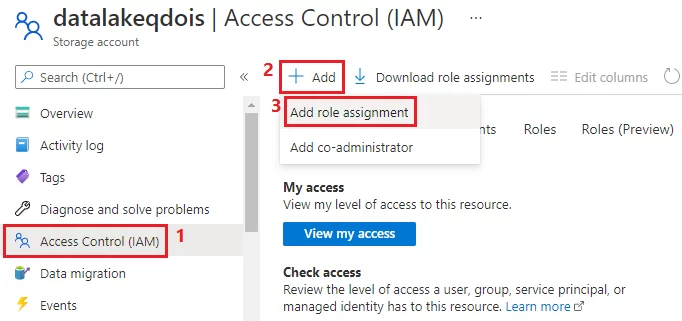
- Na janela Add role assignment, selecione o role adequado para a sua situação e, em seguida, procure o nome do Service Principal para atribuir esse role a ele. Após salvar o role criado, ele aparecerá listado na lista de Role Assignments.

Criando um mount point do Azure Data Lake Storage Gen2 usando uma entidade de serviço e OAuth 2.0
Após definir as regras de controle de acesso, você pode montar um Azure Data Lake Storage Gen2 no Databricks File System (DBFS), usando seu Service Principal e o protocolo OAuth 2.0. Mount points funcionam como um ponteiro para a conta de armazenamento do Azure Data Lake. Portanto, os dados nunca são sincronizados localmente e podem ser acessados a partir de qualquer notebook dentro do mesmo workspace do Databricks.
Nesse processo, vamos utilizar os seguintes valores:
- application-id: Application (client) ID que você obtém ao registrar sua aplicação no Azure AD.
- directory-id: Directory (tenant) ID que você obtém ao registrar sua aplicação no Azure AD.
- storage-account-name: O nome de sua conta de armazenamento Azure Data Lake Gen2.
- scope-name: O nome do seu Secret Scope conectando o Azure Databricks ao Azure Key Vault.
- service-credential-key-name: O nome do segredo no Azure Key Vault que você criou para armazenar a senha do seu Service Principal.
Dentro do seu Databricks Workspace, crie um notebook chamado ‘mount_ADLS’. Posteriormente, execute os seguintes comandos Python, preenchendo os valores mencionados com as informações corretas:
configs = {"fs.azure.account.auth.type": "OAuth",
"fs.azure.account.oauth.provider.type": "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider",
"fs.azure.account.oauth2.client.id": "<application-id>",
"fs.azure.account.oauth2.client.secret": dbutils.secrets.get(scope="<scope-name>",key="<service-credential-key-name>"),
"fs.azure.account.oauth2.client.endpoint": "https://login.microsoftonline.com/<directory-id>/oauth2/token"}
# Opcionalmente, você pode adicionar <nome-do-seu-diretorio> à URl do seu mount point.
dbutils.fs.mount(
source = "abfss://<nome-do-seu-container>@<nome-da-sua-conta-de-armazenamento>.dfs.core.windows.net/",
mount_point = "/mnt/<nome-do-seu-mount>",
extra_configs = configs) <nome-do-seu-container> se refere ao file system do data lake (ou container) do qual você quer criar o mount point no DBFS. Do mesmo modo, <nome-do-seu-mount> é o diretório no DBFS que representará onde esse container do seu data lake será montado. Assim, para simplificar esta configuração, você pode usar o mesmo nome do seu container do ADLS dentro do Databricks.
Depois que o seu container do ADLS foi montado para o DBFS, você pode se referir ao seu mount point diretamente para acessar os arquivos dentro dele:
df = spark.read.csv("/mnt/%s/...." % <nome-do-seu-mount>)
df = spark.read.csv("dbfs:/mnt/<nome-do-seu-mount>/....") Caso precise desmontar o seu mount point, use o seguinte comando:
dbutils.fs.unmount("/mnt/<nome-do-seu-mount>") Só para ilustrar nossa configuração, tentei acessar o arquivo ‘melhores-atacantes-do-mundo.csv’, localizado dentro do container ‘test’.
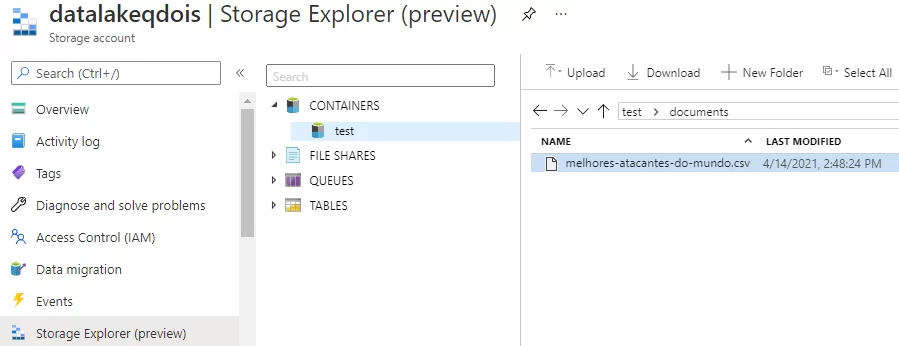
Usando os comandos Python descritos anteriormente, fui capaz de criar o mount point para o container ‘test’:

Depois disso, é só usar o mount point para ler o arquivo csv diretamente:
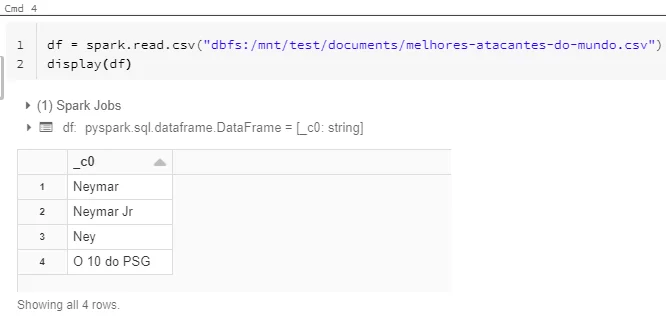
Por fim, dadas as informações dentro do meu arquivo, podemos confirmar que a configuração foi feita corretamente, não é mesmo?
Nota: Se, eventualmente, você esbarrar no erro 403 ao tentar acessar um arquivo usando seu mount point, revise os passos descritos. Isso pode acontecer se você tentar acessar o arquivo logo após conceder ao Service Principal o role no ADLS Gen 2. Assim sendo, tente novamente após aguardar alguns minutos para que o Azure possa configurar as permissões adequadas.
Espero que você tenha entendido como acessar arquivos dentro de sua conta Azure Data Lake Storage Gen 2, a partir do Azure Databricks, usando uma solução segura e simples. Existem soluções mais sofisticadas, que envolvem a criação de Listas de Controle de Acesso (ACLs) dentro do Data Lake usando o Azure Storage Explorer. Contudo, podemos mergulhar nisso em outro post. Até mais!




